diff --git a/mkdocs.yml b/mkdocs.yml
index 427e36d..2651f41 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -184,6 +184,7 @@ nav:
- MoveIt Basics: ./ros2/moveit_basics.md
- MoveIt with RViz: ./ros2/moveit_rviz_demo.md
- MoveGroup C++ API: ./ros2/moveit_movegroup_demo.md
+ - MoveIt Draw: ./ros2/moveit_draw.md
- Follow Joint Trajectory Commands: ./ros2/follow_joint_trajectory.md
# - Perception: ./ros2/perception.md
# - ArUco Marker Detection: ./ros2/aruco_marker_detection.md
@@ -202,6 +203,9 @@ nav:
# - Voice to Text: ./ros2/example_8.md
# - Voice Teleoperation of Base: ./ros2/example_9.md
- Tf2 Broadcaster and Listener: ./ros2/example_10.md
+ - Obstacle Avoider: ./ros2/obstacle_avoider.md
+ - Align to ArUco: ./ros2/align_to_aruco.md
+ - Deep Perception: ./ros2/deep_perception.md
# - PointCloud Transformation: ./ros2/example_11.md
# - ArUco Tag Locator: ./ros2/example_12.md
diff --git a/ros2/align_to_aruco.md b/ros2/align_to_aruco.md
new file mode 100644
index 0000000..963e1e8
--- /dev/null
+++ b/ros2/align_to_aruco.md
@@ -0,0 +1,116 @@
+# Align to ArUco
+ArUco markers are a type of fiducials that are used extensively in robotics for identification and pose estimation. In this tutorial we will learn how to identify ArUco markers with the ArUco detection node and enable Stretch to navigate and align itself with respect to the marker.
+
+## ArUco Detection
+Stretch uses the OpenCV ArUco detection library and is configured to identify a specific set of ArUco markers belonging to the 6x6, 250 dictionary. To understand why this is important, please refer to this handy guide provided by OpenCV.
+
+Stretch comes preconfigured to identify ArUco markers. The ROS node that enables this is the detect_aruco_markers node in the stretch_core package. Thanks to this node, identifying and estimating the pose of a marker is as easy as pointing the camera at the marker and running the detection node. It is also possible and quite convenient to visualize the detections with RViz.
+
+## Computing Transformations
+If you have not already done so, now might be a good time to review the tf_tranformation tutorial. Go on, we can wait…
+Now that we know how to program stretch to return the transform between known reference frames, we can use this knowledge to compute the transform between the detected marker and the robot base_link.. Enter TF transformations! From its current pose, for Stretch to align itself in front of the marker, we need to command it to reach there. But even before that, we need to program Stretch to know the goal pose. We define the goal pose to be 0.5 metre outward from the marker in the marker negative y-axis (Green axis). This is easier to visualize through the figure below.
+
+
+  +
+
+
+
+
+By monitoring the /aruco/marker_array and /aruco/axes topics, we can visualize the markers in RViz. The detection node also publishes the tf pose of the detected markers. This can be visualized by using the TF plugin and selecting the detected marker to inspect the pose. Next, we will use exactly that to compute the transform between the detected marker and the base_link of the robot.
+
+Now, we can compute the transformation from the robot base_link frame to the goal pose and pass this is an SE3 pose to the mobile base.
+
+Since we want Stretch to align with respect to the marker we define a 0.5m offset in the marker y-axis where Stretch would come to a stop. At the same time, we also want Stretch to point the arm towards the marker so as to make the subsequent manipulation tasks easier to accomplish. This would result in the end pose of the base_link as shown below. Sweet! The next task is to plan a trajectory for the mobile base to reach this end pose. We do this in three steps:
+1. Turn theta degrees towards the goal position
+2. Travel straight to the goal position
+3. Turn phi degrees to attain the goal orientation
+
+Luckily, we know how to command Stretch to execute a trajectory using the joint trajectory server. If you are just starting, have a look at the tutorial to know how to command Stretch using the Joint trajectory Server.
+
+## Warnings
+Since we won't be using the arm for this demo, it's safer to stow Stretch's arm in. Execute the command:
+```bash
+stretch_robot_stow.py
+```
+
+## See It In Action
+First, we need to point the camera towards the marker. To do this, you could use the keyboard teleop node.
+When you are ready, execute the following command:
+```bash
+ros2 launch stretch_core align_to_aruco.launch.py
+```
+
+
+  +
+
+
+## Code Breakdown
+Let's jump into the code to see how things work under the hood. Follow along here to have a look at the entire script.
+
+We make use of two separate Python classes for this demo. The FrameListener() class is derived from the Node class and is the place where we compute the TF transformations. For an explantion of this class, you can refer to the TF listener tutorial.
+```python
+class FrameListener(Node):
+```
+
+The AlignToAruco() class is where we command Stretch to the pose goal. This class is derived from the FrameListener class so that they can both share the node instance.
+```python
+class AlignToAruco(FrameListener):
+```
+
+The constructor initializes the Joint trajectory action client. It also initialized the attribute called offset that determines the end distance between the marker and the robot.
+```python
+ def __init__(self, node, offset=0.75):
+ self.trans_base = TransformStamped()
+ self.trans_camera = TransformStamped()
+ self.joint_state = JointState()
+ self.offset = offset
+ self.node = node
+
+ self.trajectory_client = ActionClient(self.node, FollowJointTrajectory, '/stretch_controller/follow_joint_trajectory')
+ server_reached = self.trajectory_client.wait_for_server(timeout_sec=60.0)
+ if not server_reached:
+ self.node.get_logger().error('Unable to connect to arm action server. Timeout exceeded.')
+ sys.exit()
+```
+
+The joint_states_callback is the callback method that receives the most recent joint state messages published on the /stretch/joint_states topic.
+```python
+ def joint_states_callback(self, joint_state):
+ self.joint_state = joint_state
+```
+
+The copute_difference() method is where we call the get_transform() method from the FrameListener class to compute the difference between the base_link and base_right frame with an offset of 0.5 m in the negative y-axis.
+```python
+ def compute_difference(self):
+ self.trans_base, self.trans_camera = self.node.get_transforms()
+```
+
+To compute the (x, y) coordinates of the SE3 pose goal, we compute the transformation as explained above here.
+```python
+ R = quaternion_matrix((x, y, z, w))
+ P_dash = np.array([[0], [-self.offset], [0], [1]])
+ P = np.array([[self.trans_base.transform.translation.x], [self.trans_base.transform.translation.y], [0], [1]])
+
+ X = np.matmul(R, P_dash)
+ P_base = X + P
+
+ base_position_x = P_base[0, 0]
+ base_position_y = P_base[1, 0]
+```
+
+From this, it is relatively straightforward to compute the angle phi and the euclidean distance dist. We then compute the angle z_rot_base to perform the last angle correction.
+```python
+ phi = atan2(base_position_y, base_position_x)
+
+ dist = sqrt(pow(base_position_x, 2) + pow(base_position_y, 2))
+
+ x_rot_base, y_rot_base, z_rot_base = euler_from_quaternion([x, y, z, w])
+ z_rot_base = -phi + z_rot_base + 3.14159
+```
+
+The align_to_marker() method is where we command Stretch to the pose goal in three steps using the Joint Trajectory action server. For an explanation on how to form the trajectory goal, you can refer to the Follow Joint Trajectory tutorial.
+```python
+ def align_to_marker(self):
+```
+
+The End! If you want to work with a different ArUco marker than the one we used in this tutorial, you can do so by changing line 44 in the code to the one you wish to detect. Also, don't forget to add the marker in the ArUco marker dictionary.
diff --git a/ros2/deep_perception.md b/ros2/deep_perception.md
new file mode 100644
index 0000000..472ad5b
--- /dev/null
+++ b/ros2/deep_perception.md
@@ -0,0 +1,196 @@
+# Deep Perception
+Ever wondered if there is a way to make a robot do awesome things without explicitly having to program it to do so? Deep Perception is a branch of Deep Learning that enables sensing the elements that make up an environment with the help of artificial neural networks without writing complicated code. Well, almost. The most wonderful thing about Stretch is that it comes preloaded with software that makes it a breeze to get started with topics such as Deep Learning. In this tutorial, we will deploy deep neural networks on Stretch using two popular Deep Learning frameworks, namely, PyTorch and OpenVino.
+
+## YOLOv5 with PyTorch
+PyTorch is an open source end-to-end machine learning framework that makes many pretrained production quality neural networks available for general use. In this tutorial we will use the YOLOv5s model trained on the COCO dataset.
+
+YOLOv5 is a popular object detection model that divides a supplied image into a grid and detects objects in each cell of the grid recursively. The YOLOv5s model that we have deployed on Stretch has been pretrained on the COCO dataset which allows Stretch to detect a wide range of day to day objects. However, that’s not all, in this demo we want to go a step further and use this extremely versatile object detection model to extract useful information about the scene.
+
+## Extracting Bounding Boxes and Depth Information
+Often, it’s not enough to simply identify an object. Stretch is a mobile manipulator and its job is to manipulate objects in its environment. But before it can do that, it needs information of where exactly the object is located with respect to itself so that a motion plan to reach the object can be generated. This is possible by knowing which pixels correspond to the object of interest in the image frame and then using that to extract the depth information in the camera frame. Once we have this information, it is possible to compute a transform of these points in the end effector frame for Stretch to generate a motion plan.
+
+For the sake of brevity, we will limit the scope of this tutorial to drawing bounding boxes around objects of interest to point to pixels in the image frame, and drawing a detection plane corresponding to depth pixels in the camera frame.
+
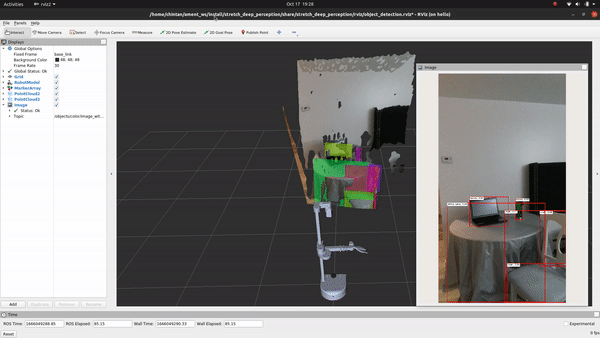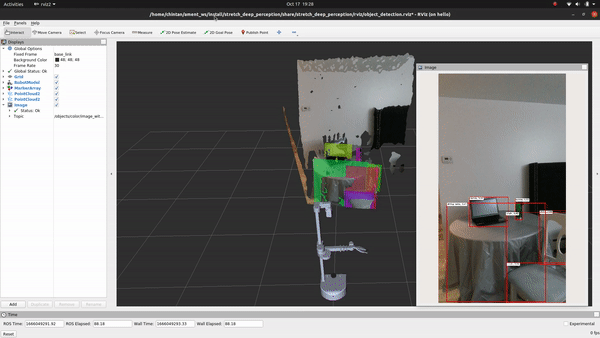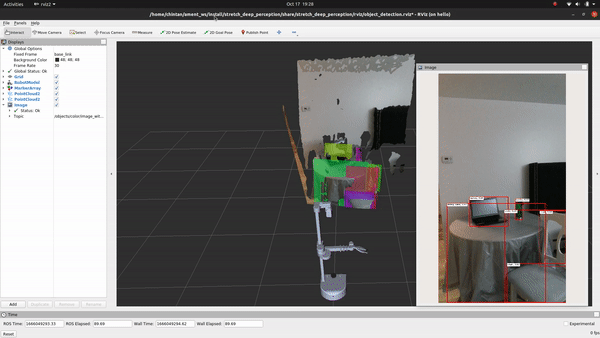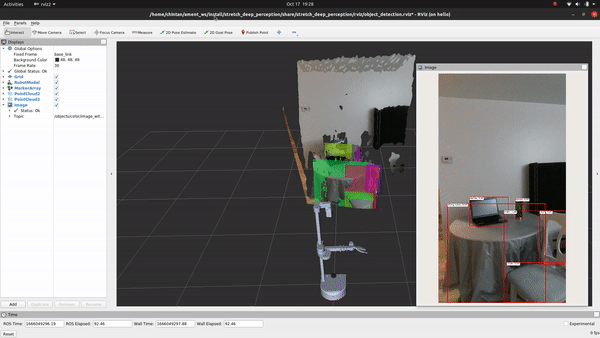
+## See It In Action
+Go ahead and execute the following command to run the inference and visualize the detections in RViz:
+
+```
+ros2 launch stretch_deep_perception stretch_detect_objects.launch.py
+```
+
+
+
+Voila! You just executed your first deep learning model on Stretch!
+
+## Code Breakdown
+Luckily, the stretch_deep_pereption package is extremely modular and is designed to work with a wide array of detectors. Although most of the heavy lifting in this tutorial is being done by the neural network, let's attempt to breakdown the code into funtional blocks to understand the detection pipeline.
+
+The control flow begins with executing the detect_objects.py node. In the main() function, we create an instance of the ObjectDetector class from the object_detect_pytorch.py script where we configure the YOLOv5s model. Next, we pass this detector to an instance of the DetectionNode class from the detection_node.py script and call the main function.
+```python
+def main():
+ confidence_threshold = 0.0
+ detector = od.ObjectDetector(confidence_threshold=confidence_threshold)
+ default_marker_name = 'object'
+ node_name = 'DetectObjectsNode'
+ topic_base_name = 'objects'
+ fit_plane = False
+ node = dn.DetectionNode(detector, default_marker_name, node_name, topic_base_name, fit_plane)
+ node.main()
+```
+
+Let's skim through the object_detect_pytorch.py script to understand the configuration. The constructor is where we load the pretrained YOLOv5s model using the torch.hub.load() PyTorch wrapper. We set the confidence threshold to be 0.2, which says that a detection is only considered valid if the probability is higher than 0.2. This can be tweaked, although lower numbers often result in false positives and higher numbers often disregard blurry or smaller valid objects.
+```python
+class ObjectDetector:
+ def __init__(self, confidence_threshold=0.2):
+ # Load the models
+ self.model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5l, yolov5x, custom
+ self.confidence_threshold = confidence_threshold
+```
+The apply_to_image() method passes the stream of RGB images from the realsense camera to the YOLOv5s model and returns detections in the form of a dictionary consisting of class_id, label, confidence and bouding box coordinates. The last part is exactly what we need for further computations.
+```python
+def apply_to_image(self, rgb_image, draw_output=False):
+ results = self.model(rgb_image)
+
+ ...
+
+ if draw_output:
+ output_image = rgb_image.copy()
+ for detection_dict in results:
+ self.draw_detection(output_image, detection_dict)
+
+ return results, output_image
+```
+
+This method calls the draw_detection() method to draw bounding boxes with the object labels and confidence thresholds over detected objects in the image using OpenCV.
+```python
+def draw_detection(self, image, detection_dict):
+ ...
+
+ cv2.rectangle(image, (x_min, y_min), (x_max, y_max), color, rectangle_line_thickness)
+
+ ...
+
+ cv2.rectangle(image, (label_x_min, label_y_min), (label_x_max, label_y_max), (255, 255, 255), cv2.FILLED)
+ cv2.putText(image, output_string, (text_x, text_y), font, font_scale, line_color, line_width, cv2.LINE_AA)
+```
+
+Next, the script detection_node.py contains the class DetectionNode which is the main ROS node that subscribes to the RGB and depth images from the realsense camera and feeds them to the detector to run inference. The image_callback() method runs in a loop to subscribe to synchronized RGB and depth images. The RGB images are then rotated 90 degrees and passed to the apply_to_image() method. The returned output image is published on the visualize_object_detections_pub publisher, while the detections_2d dictionary is passed to the detections_2d_to_3d() method for further processing and drawing the detection plane. For detectors that also return markers and axes, it also publishes this information.
+```python
+def image_callback(self, ros_rgb_image, ros_depth_image, rgb_camera_info):
+ ...
+
+ detection_box_image = cv2.rotate(self.rgb_image, cv2.ROTATE_90_CLOCKWISE)
+
+ ...
+
+ detections_2d, output_image = self.detector.apply_to_image(detection_box_image, draw_output=debug_output)
+
+ ...
+
+ if output_image is not None:
+ output_image = ros2_numpy.msgify(Image, output_image, encoding='rgb8')
+ if output_image is not None:
+ self.visualize_object_detections_pub.publish(output_image)
+
+ detections_3d = d2.detections_2d_to_3d(detections_2d, self.rgb_image, self.camera_info, self.depth_image, fit_plane=self.fit_plane, min_box_side_m=self.min_box_side_m, max_box_side_m=self.max_box_side_m)
+
+ ...
+
+ if self.publish_marker_point_clouds:
+ for marker in self.marker_collection:
+ marker_points = marker.get_marker_point_cloud()
+ self.add_point_array_to_point_cloud(marker_points)
+ publish_plane_points = False
+ if publish_plane_points:
+ plane_points = marker.get_plane_fit_point_cloud()
+ self.add_point_array_to_point_cloud(plane_points)
+ self.publish_point_cloud()
+ self.visualize_markers_pub.publish(marker_array)
+ if axes_array is not None:
+ self.visualize_axes_pub.publish(axes_array)
+```
+
+## Face Detection, Facial Landmarks Detection and Head Pose Estimation with OpenVINO and OpenCV
+OpenVINO is a toolkit popularized by Intel to optimize and deploy machine learning inference that can utilize hardware acceleration dongles such as the Intel Neural Compute Stick with Intel based compute architectures. More convenient is the fact that most of the deep learning models in the Open Model Zoo are accessible and configurable using the familiar OpenCV API with the opencv-python-inference-engine library.
+
+With that, let’s jump right into it! Detecting objects is just one thing Stretch can do well, it can do much more using pretrained models. For this part of the tutorial, we will be using Intel’s OpenVINO toolkit with OpenCV. The cool thing about this demo is that it uses three different models in tandem to not just detect human faces, but also important features of the human face such as the eyes, nose and the lips with head pose information. This is important in the context of precise manipulation tasks such as assisted feeding where we want to know the exact location of the facial features the end effector must reach.
+
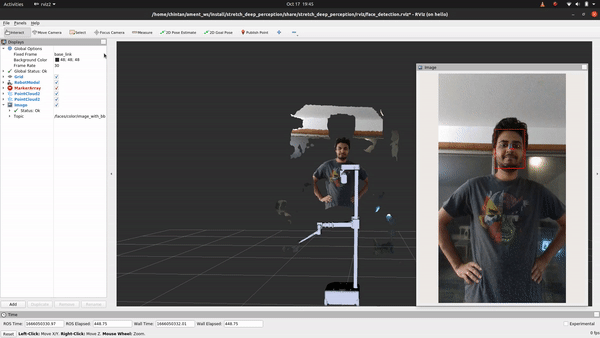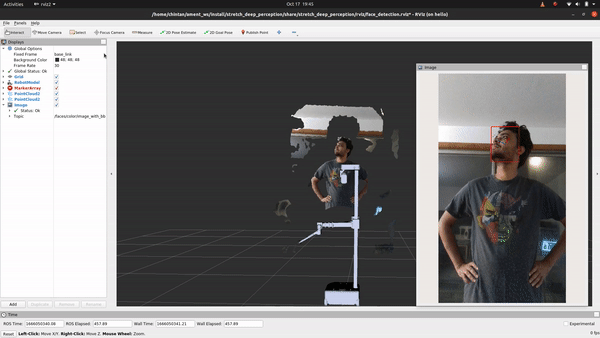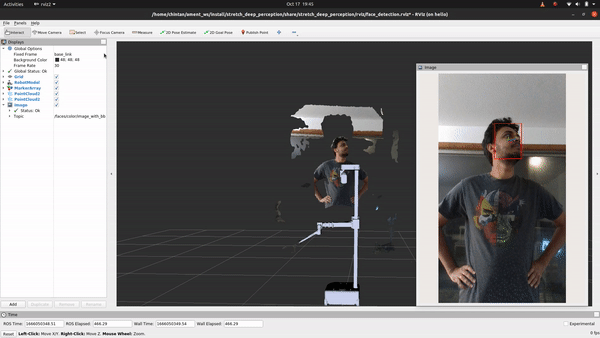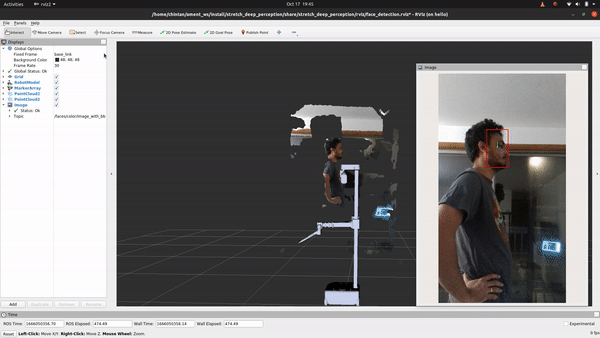
+## See It In Action
+First, let’s execute the following command to see what it looks like:
+
+```
+ros2 launch stretch_deep_perception stretch_detect_faces.launch.py
+```
+
+
+
+## Code Breakdown
+Ain't that something! If you followed the breakdown in object detection, you'll find that the only change if you are looking to detect faces instead of objects is in using a different deep learning model that does just that. For this, we will explore how to use the OpenVINO toolkit. Let's head to the detect_faces.py node to begin.
+
+In the main() method, we see a similar structure as with the object detction node. We first create an instance of the detector using the HeadPoseEstimator class from the head_estimator.py script to configure the deep learning models. Next, we pass this to an instance of the DetectionNode class from the detection_node.py script and call the main function.
+```python
+ ...
+
+ detector = he.HeadPoseEstimator(models_directory,
+ use_neural_compute_stick=use_neural_compute_stick)
+ default_marker_name = 'face'
+ node_name = 'DetectFacesNode'
+ topic_base_name = 'faces'
+ fit_plane = False
+ node = dn.DetectionNode(detector,
+ default_marker_name,
+ node_name,
+ topic_base_name,
+ fit_plane,
+ min_box_side_m=min_head_m,
+ max_box_side_m=max_head_m)
+ node.main()
+```
+
+In addition to detecting faces, this class also enables detecting facial landmarks as well as estimating head pose. The constructor initializes and configures three separate models, namely head_detection_model, head_pose_model and landmarks_model, with the help of the renamed_cv2.dnn.readNet() wrappers. Note that renamed_cv2 is simply the opencv_python_inference_engine library compiled under a different namespace for using with Stretch so as not to conflict with the regular OpenCV library and having functionalities from both available to users concurrently.
+```python
+class HeadPoseEstimator:
+ def __init__(self, models_directory, use_neural_compute_stick=False):
+ ...
+
+ self.head_detection_model = renamed_cv2.dnn.readNetFromCaffe(head_detection_model_prototxt_filename, head_detection_model_caffemodel_filename)
+ dm.print_model_info(self.head_detection_model, 'head_detection_model')
+
+ ...
+
+ self.head_pose_model = renamed_cv2.dnn.readNet(head_pose_weights_filename, head_pose_config_filename)
+
+ ...
+
+ self.landmarks_model = renamed_cv2.dnn.readNet(landmarks_weights_filename, landmarks_config_filename)
+```
+
+The apply_to_image() method calls individual methods like detect_faces(), estimate_head_pose() and detect_facial_landmarks() that each runs the inference using the models we configured above. The bounding_boxes from the face detection model are used to supply the cropped image of the faces to head pose and facial landmark models to make their job way more efficient.
+```python
+ def apply_to_image(self, rgb_image, draw_output=False):
+ ...
+
+ boxes = self.detect_faces(rgb_image)
+
+ facial_landmark_names = self.landmark_names.copy()
+ for bounding_box in boxes:
+ if draw_output:
+ self.draw_bounding_box(output_image, bounding_box)
+ yaw, pitch, roll = self.estimate_head_pose(rgb_image, bounding_box, enlarge_box=True, enlarge_scale=1.15)
+ if yaw is not None:
+ ypr = (yaw, pitch, roll)
+ if draw_output:
+ self.draw_head_pose(output_image, yaw, pitch, roll, bounding_box)
+ else:
+ ypr = None
+ landmarks, landmark_names = self.detect_facial_landmarks(rgb_image, bounding_box, enlarge_box=True, enlarge_scale=1.15)
+ if (landmarks is not None) and draw_output:
+ self.draw_landmarks(output_image, landmarks)
+ heads.append({'box':bounding_box, 'ypr':ypr, 'landmarks':landmarks})
+
+ return heads, output_image
+```
+
+The detecion_node.py script then takes over as we saw with the object detection tutorial to publish the detections on pertinent topics.
+
+Now go ahead and experiment with a few more pretrained models using PyTorch or OpenVINO on Stretch. If you are feeling extra motivated, try creating your own neural networks and training them. Stretch is ready to deploy them.
diff --git a/ros2/moveit_draw.md b/ros2/moveit_draw.md
new file mode 100644
index 0000000..e69de29
diff --git a/ros2/obstacle_avoider.md b/ros2/obstacle_avoider.md
new file mode 100644
index 0000000..8505976
--- /dev/null
+++ b/ros2/obstacle_avoider.md
@@ -0,0 +1,90 @@
+# Obstacle Avoider
+In this tutorial we will work with Stretch to detect and avoid obstacles using the onboard RPlidar A1 laser scanner and learn how to filter laser scan data. If you want to know more about the laser scanner setup on Stretch and how to get it up and running, we recommend visiting the previous tutorials on filtering laser scans and mobile base collision avoidance.
+
+A major drawback of using any ToF (Time of Flight) sensor is the inherent inaccuracies as a result of occlusions and weird reflection and diffraction phenomena the light pulses are subject to in an unstructured environment. This results in unexpected and undesired noise that can get in the way of an otherwise extremely useful sensor. Fortunately, it is easy to account for and eliminate these inaccuracies to a great extent by filering out the noise. We will do this with a ROS package called laser_filters that comes prebuilt with some pretty handy laser scan message filters.
+
+By the end of this tutorial, you will be able to tweak them for your particular use case and publish and visualize them on the /scan_filtered topic using RViz. So let’s jump in! We will look at three filters from this package that have been tuned to work well with Stretch in an array of scenarios.
+
+## LaserScan Filtering
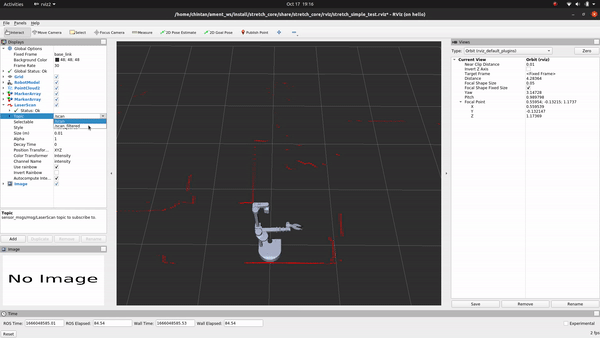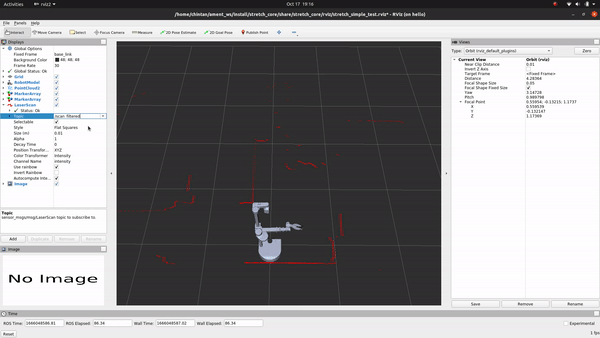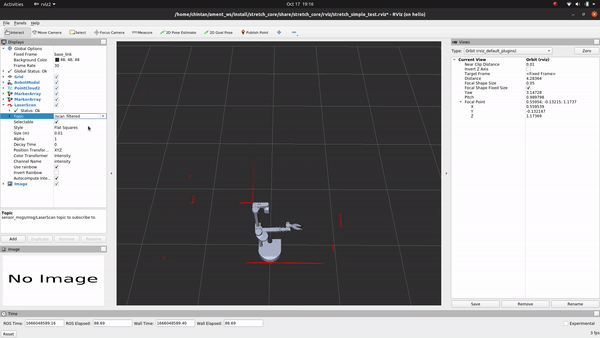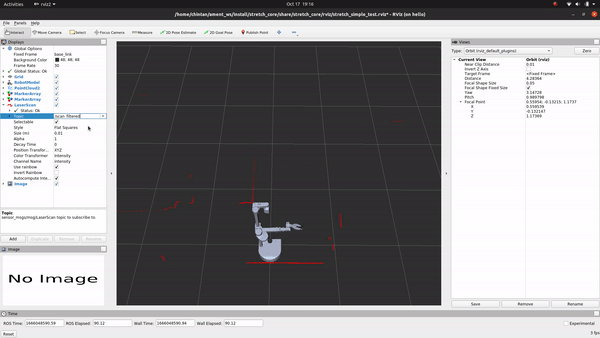
+LaserScanAngularBoundsFilterInPlace - This filter removes laser scans belonging to an angular range. For Stretch, we use this filter to discount points that are occluded by the mast because it is a part of Stretch’s body and not really an object we need to account for as an obstacle while navigating the mobile base.
+
+LaserScanSpeckleFilter - We use this filter to remove phantom detections in the middle of empty space that are a result of reflections around corners. These disjoint speckles can be detected as false positives and result in jerky motion of the base through empty space. Removing them returns a relatively noise-free scan.
+
+LaserScanBoxFilter - Stretch is prone to returning false detections right over the mobile base. While navigating, since it’s safe to assume that Stretch is not standing right above an obstacle, we filter out any detections that are in a box shape over the mobile base.
+
+However, beware that filtering laser scans comes at the cost of a sparser scan that might not be ideal for all applications. If you want to tweak the values for your end application, you could do so by changing the values in the laser_filter_params.yaml file and by following the laser_filters package wiki. Also, if you are feeling zany and want to use the raw unfiltered scans from the laser scanner, simply subscribe to the /scan topic instead of the /scan_filtered topic.
+
+
+
+## Avoidance logic
+Now, let’s use what we have learned so far to upgrade the collision avoidance demo in a way that Stretch is able to scan an entire room autonomously without bumping into things or people. To account for dynamic obstacles getting too close to the robot, we will define a keepout distance of 0.4 m - detections below this value stop the robot. To keep Stretch from getting too close to static obstacles, we will define another variable called turning distance of 0.75 m - frontal detections below this value make Stretch turn to the left until it sees a clear path ahead.
+
+Building up on the teleoperation using velocity commands tutorial, let's implement a simple logic for obstacle avoidance. The logic can be broken down into three steps:
+1. If the minimum value from the frontal scans is greater than 0.75 m then continue to move forward
+2. If the minimum value from the frontal scans is less than 0.75 m then turn to the right until this is no longer true
+3. If the minimum value from the overall scans is less than 0.4 m then stop the robot
+
+## Warnings
+If you see Stretch try to run over your lazy cat or headbutt a wall, just press the bright runstop button on Stretch's head to calm it down. For pure navigation tasks, it's also safer to stow Stretch's arm in. Execute the command:
+```bash
+stretch_robot_stow.py
+```
+
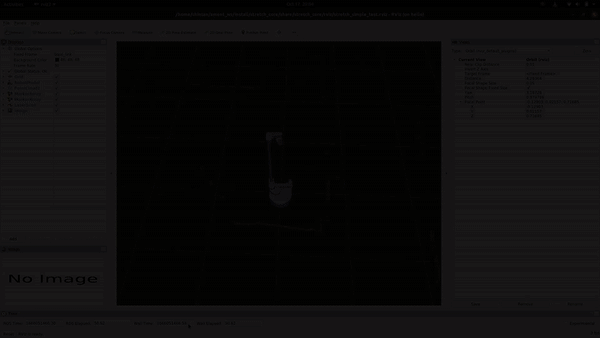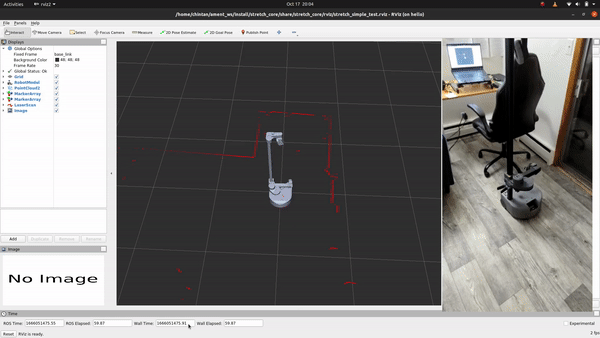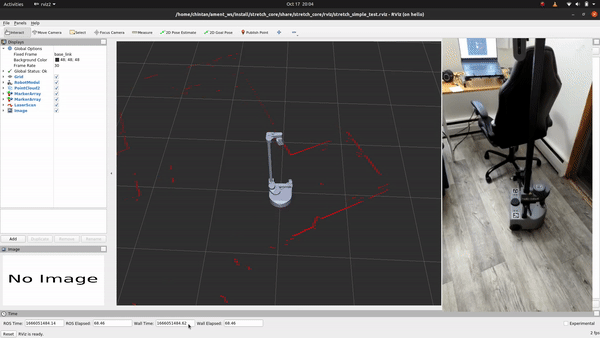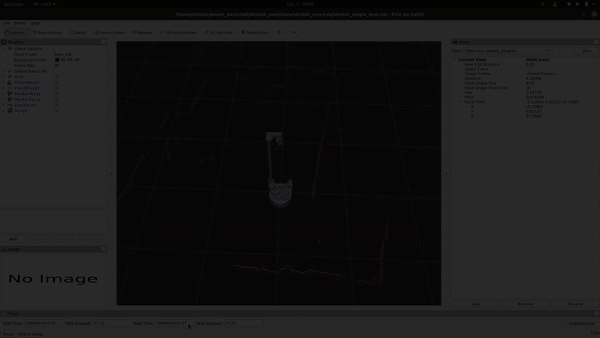
+## See It In Action
+Alright, let's see it in action! Execute the following command to run the scripts:
+```bash
+ros2 launch stretch_core rplidar_keepout.launch.py
+```
+
+
+
+## Code Breakdown:
+Let's jump into the code to see how things work under the hood. Follow along here to have a look at the entire script.
+
+The turning distance is defined by the distance attribute and the keepout distance is defined by the keepout attribute.
+```python
+ self.distance = 0.75 # robot turns at this distance
+ self.keepout = 0.4 # robot stops at this distance
+```
+
+To pass velocity commands to the mobile base we publish the translational and rotational velocities to the /stretch/cmd_vel topic. To subscribe to the filtered laser scans from the laser scanner, we subscribe to the /scan_filtered topic. While you are at it, go ahead and check the behavior by switching to the /scan topic instead. You're welcome!
+```python
+ self.publisher_ = self.create_publisher(Twist, '/stretch/cmd_vel', 1) #/stretch_diff_drive_controller/cmd_vel for gazebo
+ self.subscriber_ = self.create_subscription(LaserScan, '/scan_filtered', self.lidar_callback, 10)
+```
+
+This is the callback function for the laser scanner that gets called every time a new message is received.
+```python
+def lidar_callback(self, msg):
+```
+
+When the scan message is filtered, all the ranges that are filtered out are assigned the nan (not a number) value. This can get in the way of computing the minimum. Therefore, we reassign these values to inf (infinity).
+```python
+ all_points = [r if (not isnan(r)) else inf for r in msg.ranges]
+```
+
+Next, we compute the two minimums that are neccessary for the avoidance logic to work - the overall minimum and the frontal minimum named min_all and min_front respectively.
+```python
+ front_points = [r * sin(theta) if (theta < -2.5 or theta > 2.5) else inf for r,theta in zip(msg.ranges, angles)]
+ front_ranges = [r if abs(y) < self.extent else inf for r,y in zip(msg.ranges, front_points)]
+
+ min_front = min(front_ranges)
+ min_all = min(all_points)
+```
+
+Finally, we check the minimum values against the distance and keepout attributes to set the rotational and linear velocities of the mobile base with the set_speed() method.
+```python
+ if(min_all < self.keepout):
+ lin_vel = 0.0
+ rot_vel = 0.0
+ elif(min_front < self.distance):
+ lin_vel = 0.0
+ rot_vel = 0.25
+ else:
+ lin_vel = 0.5
+ rot_vel = 0.0
+
+ self.set_speed(lin_vel, rot_vel)
+```
+
+That wasn't too hard, was it? Feel free to play with this code and change the attributes to see how it affects Stretch's behavior.